



The Skateboarding Teddy Bear That Reinvented Media
Composable Diffusion is an AI That Turns Anything into Anything
Last week, a video of a teddy bear skateboarding through the rainy streets of New York City showed up on the Internet. Its fidelity, 2-second length and sheer randomness gave it the appearance of a hastily assembled GIF. The origin of the video is almost infinitely more complex.
‘Teddy Bear on a Skateboard‘ is an early output of Composable Diffusion (CODI), a multimodal AI system built by a team at Microsoft. CODI can transform any combination of text, video and/or audio into any other combination of text, video and/or audio. The ‘Teddy bear on a Skateboard’ video was produced solely with a text description and an image of Times Square.
The technology is dubbed an ‘any-to-any model’, as in any combination of media formats into any other type of media formats. It signals a radical new approach to media composability. This is the story of CODI and its potential to revolutionize every aspect of online communications.
Where We’re At, Modally
A point of clarification. I use the word modality a lot in this article. In the parlance of machine learning, modalities are the familiar formats we use for digital interactions, like audio, video, text, and images. OK, let’s go.
At this moment in time, a significant portion of the Internet-going population has tried, or at the very least heard of, AI image generators like MidJourney, Imagen, Dall-E or Stable Diffusion. While numbers are scant, MidJourney alone processes roughly 30 images per second. That’s North of 2.5 million images per day, and just south of a billion images per year. Shyeah.
The short-hand for these generators are ‘text-to-image’ models. The architecture of text-to-image models vary, but they all function pretty much the same way. A human provides text input to a language model. That text is transformed into a representation that a machine can understand. Then a generative image model produces an image conditioned on that representation. Aka, human text is turned into synthetic imagery.
But text-to-image isn’t the only game in town. Dig a little deeper and you’ll discover a world of AI-powered media-to-media synthesizers. There’s text-to-image but there’s also image-to-text. There’s text-to-text, image-to-image, sketch-to-image, text-to-video, text-to-code, audio-to-text, text-to-audio, text-to-3D gaming asset… The list gets longer every day. In a very short period of time, all this AI-powered media transforming has had an outsized impact on the way us humans create and the way we work. The production pipelines of entire industries are being fundamentally redrawn in front of our eyes.
Still, we’re merely at the tip of the transformation-berg. For all their power, the generators above are merely unimodal. That is, they can only accommodate one modality in and one modality out.
Now imagine a model that can handle multiple modality inputs and provide multiple modality outputs at the same time. In this next paradigm, generators are able to render a text description and a sample image into entire films, complete with synchronized voices and sound effects.
Enter Composable Diffusion.
The Scenic Route to CODI
To understand Composable Diffusion, you first need to understand diffusion models like MidJourney and Dall-E. And to understand these diffusion models you need to understand the wider generative landscape. Here’s a no-numbers explanation:
Diffusion models are the most recent addition to a growing set of generative models that can perform functions like image generation. There’s Generative Adversarial Networks (GANs), Variational Auto-Encoders (VAEs), and Flow-Based models. We don’t need to go into all of these, but a quick look at GANs is instructive.
Introduced in 2014, GANs consist of a Generator and a Discriminator. GANs work in three steps: First, a hand-picked collection of verifiable data - lets say a lot of photos of teddy bears collected from the Internet - are fed into a discriminator. In a repetitive process called training, the discriminator gets better and better at knowing what a real teddy bear looks like. Second, a generator creates a collection of fake but plausible data - say, a lot of computer generated pictures that are sometimes teddy bears. These also get fed it into the discriminator. The discriminator compares the real images to the fake ones, then assesses what is and is not a legit teddy bear. Third, the discriminator then feeds these learnings back to the generator in a process called Back Propagation. Over time, the generator becomes increasingly good at producing teddy bears that pass the discriminator’s test, and image generation becomes more reliable.
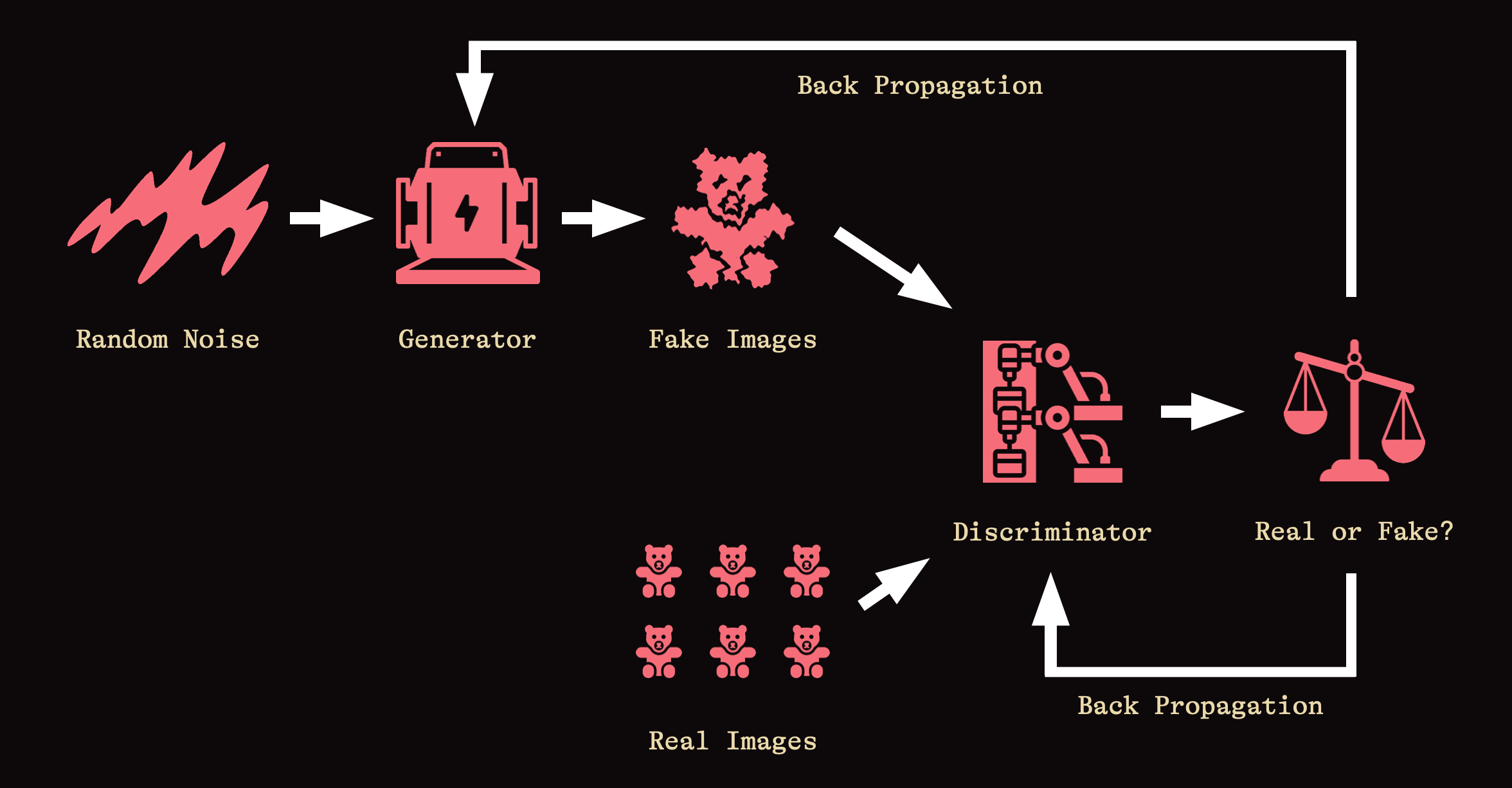
This push-and-pull relationship between generator and discriminator in GANs is described as Adversarial, and is exactly where diffusion models diverge. Instead of pummeling a discriminator, diffusion models destroy training data by adding noise and then learn to recover the data by reversing this noising process. The noising process is called forward diffusion. The de-noising process is called reverse diffusion. Diffusion models run this process back and forth along a Markov Chain, which ensures noising and de-noising are done in strict sequence. This makes it easy for the model to retrace its steps, transforming lots of noise into high-resolution images. The objective is the same: image generation becomes more reliable.

While there are pros and cons to every type of generative model, diffusion shows the most promise when it comes to a particularly in-demand feature: fine control. Despite being more computationally intensive, diffusion offers a heightened ability to manipulate the quality and diversity of an image, and ultimately achieve better ouputs.
Inside CODI
As the name suggests, Composable Diffusion combines multiple diffusion models into one framework. But that’s not the big deal. A careful reading of the CODI whitepaper is illustrative: “Our approach enables the synergistic generation of high-quality and coherent outputs spanning various modalities, from assorted combinations of input modalities,” the team holds. “Synergistic” is the key word.
CODI combines the output of multiple diffusions into a single space in which every modality can coexist, synergistically. This space is called ‘latent alignment’. In this space, modalities are positioned so that they can share information. A process called ‘bridging alignment’ then fosters cross-modal understanding. An analogy, if you might: Picture a video, an image, an audio file and some text all hanging out in an empty bar. In our example the bar is latent alignment. The booze is bridging alignment. And the barroom conversation is the output.
The secret weapon of bridging alignment is text, due to its “ubiquitous presence in paired data.” As it happens, humans label almost everything on the Internet with text. Text is used to describe videos, songs, and imagery more than another modality describes any other single modality on the web. CODI takes advantage of this tradition, using text to unite the various modalities during bridging alignment.
Here’s an example: Let’s say you use CODI to transform the text, “Teddy Bear in Water,” into a video with sound of a teddy bear floating in water. So, text-to-video+audio. As it happens, there are quite a few paired datasets on the Internet of the words “teddy bear” and videos of teddy bears. There are also many paired datasets of the text “water” and audio files containing the sound of water. Comparably, there are far less paired datasets of videos of teddy bears and sounds of water. Guided by the ubiquity of text-video and text-audio pairings, CODI is able to fill in the blanks, and output a video of a teddy bear accompanied by the sound of water, simply from a text input. This inference and then joint generation produces results that humans have never come up with before.
In a first, CODI can also output “temporally aligned” modalities. This is a breathtaking show of coordination in which video and audio are synchronized during generation.
OK enough with the teddy bears. Let’s have some fun.
Taking CODI For a Test Run
The CODI paper provides a bevy of results from the fledgling model. With each, the possibilities expand. Here are a few:
Audio + Image → Text + Image
Input: An image of a forest and the sound of a piano.
Output: An image of a pianist in the woods.

Text → Video + Audio
Input: “Fireworks in the sky”
Output: A video with sound of fireworks.
Image + Audio → Audio
Input: An image of a waterfall and the sound of birds.
Output: The sound of a waterfall and birds.
Text + Image → Video
Input: “Eating on a coffee table” and an image of a panda.
Output: A video of a panda eating at a coffee table.

Not too shabby CODI. Not too shabby.
The Impact of CODI
Microsoft’s research paper concludes with a proclamation that “our work marks a significant step towards more engaging and holistic human-computer interactions.” While CODI’s near-term applications in creative communications are fairly evident, its long-term impact on our very way of being with machines is more unwieldy.
I asked local media sorcerer and CEO of The New Computer Corporation Ben Palmer his thoughts on composable diffusion. “Maybe what we should be doing with this technology is treating it like a jazz reality synthesizer - instead of focusing on mimicking the world around us, maybe the opportunity is to delve deeper into our imaginations and create simulations in a totally freeform way.”
Maybe bestowing every imagination on earth with a multimodal AI system that can summon all data ever created will result in a triumph of individualized human expression. Or maybe we just make more GIFs.
If you’ve spent time building in the AI space, you’re probably familiar with the torrent of groundbreaking advances coming out of corporate labs and academia. Each new advance debuts as a whitepaper - a scholarly PDF jam-packed with technical detail. En masse, these papers blend into one giant innovation spitball held together by FOMO and the future.

The sheer volume and eye-glazing density of this research goes unprocessed by the very industries that will be most impacted. Nowhere does this hold more true than in the world of digital media. At this very moment, every building block of online communication is being blown to smithereens then redistributed in an ever-diversifying format continuum.
Over the course of the coming months, Lore Machine will identify and demystify seminal whitepapers in the generative media space. We will outline how this technology is changing the communications fabric of our species and provide a guide for navigating our newfound transmedia realm.